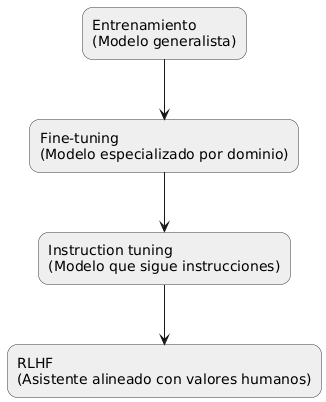
Entrenamiento: el bootcamp de los LLM
Al principio, un modelo extenso de lenguaje (LLM) es básicamente una calculadora gigante con miles de perillas al azar. El entrenamiento sirve para calibrar esas perillas. Se le lanza un océano de texto (sí, incluye tus viejos posts en foros) y se le dice: “Adiviná la próxima palabra”.
Imaginá que le metemos Wikipedia, Reddit y tu blog de 2008 en una sola cabeza que solo quiere predecir lo que viene después.
Hacelo miles de millones de veces y voilà: empieza a entender cómo se conectan las palabras y las ideas. En esta etapa, el modelo es un generalista. Sabe un poco de todo, pero todavía no puede diagnosticar una resonancia magnética ni hacer tu declaración de impuestos.

Fine-Tuning: como si el LLM eligiera una carrera
Una vez que la base está firme, el fine-tuning (ajuste fino) sirve para que el modelo “elija una carrera”. En lugar de “todo el texto del universo”, se le da un conjunto de datos más acotado y especializado. ¿Querés que entienda imágenes médicas? Le das una biblioteca de radiografías. ¿Necesitás que resuma textos legales? Le das jurisprudencia.
Fine-tuning = decirle al sabelotodo que deje de hablar de todo y se enfoque en ser útil en un solo tema.
La idea es tomar ese cerebro multitodo y pulirlo hasta que sea útil en el mundo real.
Instruction Tuning: cuando un LLM aprende a seguir indicaciones
Acá es donde el modelo deja de ser un compañero de cuarto molesto y se convierte en un asistente decente. El instruction tuning le enseña a reconocer cuando un usuario dice cosas como “Resumí esto” o “Escribime un mail”, y a responder de forma adecuada, en vez de seguir con tu frase como si fuera un actor de improvisación que no se calla.
Nadie quiere un loro: quieren un asistente que sepa cuándo estás pidiendo ayuda y cuándo simplemente estás desahogándote.
Es la diferencia entre repetir palabras y ser un amigo útil que capta si estás buscando consejo o contando una historia.
RLHF: La maestra de protocolo y buenos modales
Finalmente, tenemos el RLHF (Reinforcement Learning with Human Feedback o aprendizaje por refuerzo con feedback humano), como una Condesa de Chikoff de inteligencias artificiales. Acá entra el factor humano: personas que revisan y califican las respuestas del modelo. “Esta es útil”, “esta es rara”, “esta suena como que quiere iniciar Skynet”. El modelo aprende a preferir las respuestas que más gustan.
Es como enseñarle a un adolescente brillante a decir “por favor” y “gracias” en vez de escupir datos sin filtro.
¿La recompensa? El modelo no solo aprende datos, sino también valores: ser cortés, rechazar pedidos turbios y no dar consejos de cocina que suenan a experimento de química.
¿Por qué importa todo esto?
- Entrenamiento = conocimiento general del lenguaje.
- Fine-tuning = habilidades especializadas.
- Instruction tuning = capacidad de seguir indicaciones.
- RLHF = alineación con valores humanos.
Para empresas, investigadores o centros de salud que quieran usar IA de forma responsable, conocer estos pasos es como leer los ingredientes antes de servir el plato. Entrenar desde cero es carísimo, pero los pasos posteriores —fine-tuning, instruction tuning y RLHF— permiten adaptar estos cerebros gigantes a herramientas útiles, seguras y confiables.
